R programming for beginners (GV900)
Lesson 14: T distribution & T test
Wednesday, January 17, 2024
2 t distribution (Student’s distribution)
Question?
- Q: Why we need t distribution since we already have normal distribution?
- A: Because we don’t know the standard deviation of the population, and the sample size is small.
The t distribution is a family of distributions that look similar to the normal distribution but have heavier tails.
The t distribution is used for inference on the mean when the population standard deviation is unknown.
The t distribution is centred at zero and has a parameter called degrees of freedom.
The degrees of freedom is equal to the sample size minus one.
As the degrees of freedom increases, the t distribution approaches the normal distribution.
Code
normTail(m = 0, s = 1, df = 5, M = c(-2.5,2.5), border = "skyblue", col = NULL,
xLab = "symbol", axes = 3)
normTail(m = 0, s = 1, df = 3, M = c(-2.5,2.5), border = "blue",
xLab = "symbol", axes = 3, add = TRUE, col = NULL)
normTail(m = 0, s = 1, df = 30, M = c(-2.5,2.5), border = "purple",
xLab = "symbol", axes = 3, add = TRUE, col = NULL)
normTail(m = 0, s = 1, M = c(-2.5,2.5), border = "red",
xLab = "symbol", axes = 3, add = TRUE, col = NULL)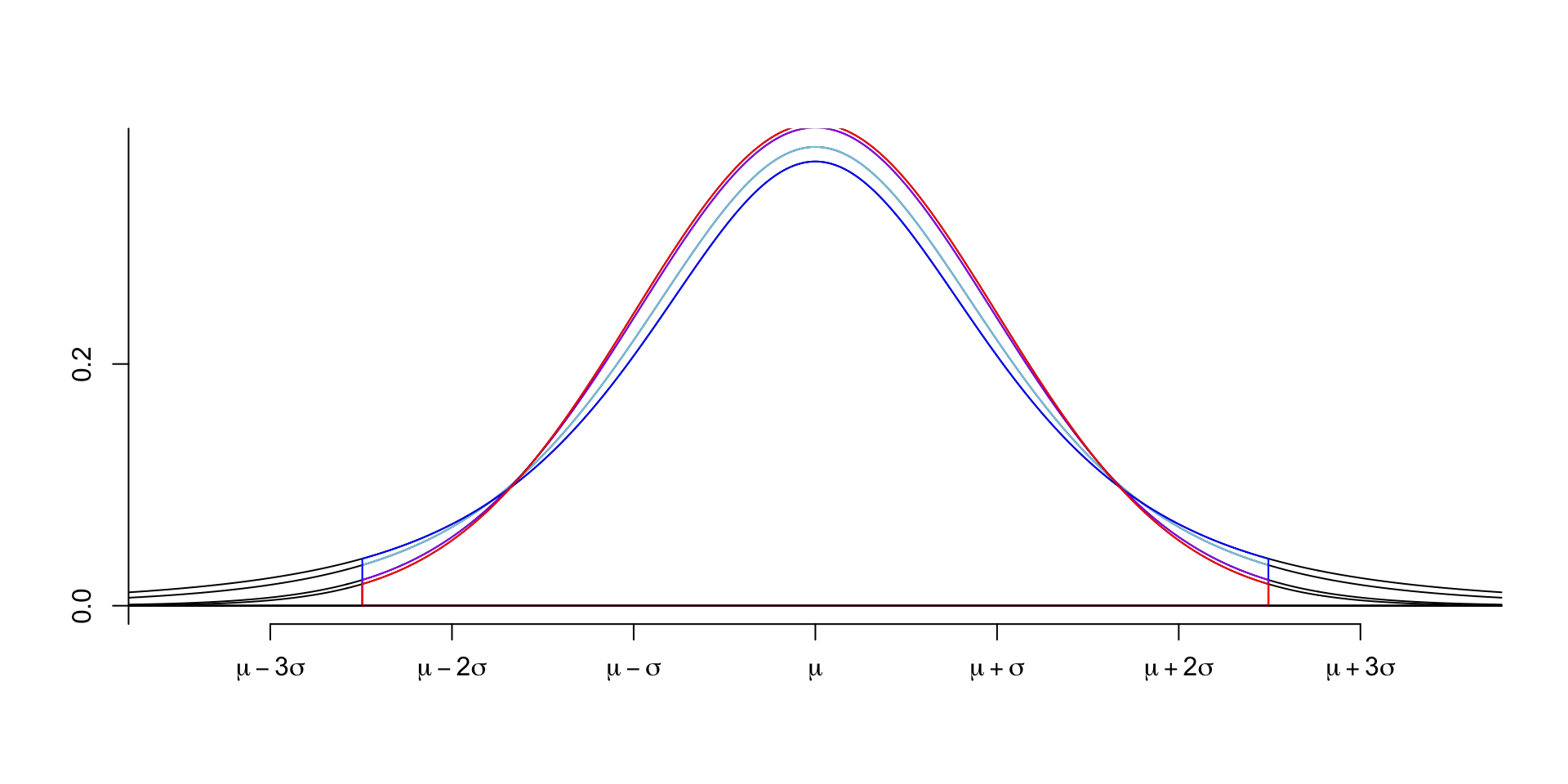
As the long tail of the t distribution, the t distribution has more probability in the tails than the normal distribution.
So, to cover the same area under the curve, the t distribution has a wider spread than the normal distribution.
And we use a larger critical value for the t distribution than the normal distribution.
Compare the formulas of confidence interval for the mean of normal distribution and t distribution.
\[\bar{x} \pm Z_{\alpha / 2} \frac{s}{\sqrt{n}}\]
\[ \bar{x} \pm t_{n-1, \alpha / 2} \frac{s}{\sqrt{n}} \]
where \({Z_{\alpha / 2}}\) is the critical value of the normal distribution and \(t_{n-1, \alpha / 2}\) is the critical value of the t distribution.
Thank you!

