R programming for beginners (GV900)
Lesson 11: Standard Deviation and Standard Error
Sunday, January 14, 2024
Video of Lesson 11
1 Setup
In this lesson, we will learn the standard deviation and the standard error.
First, load the packages we will use in this lesson.
2 Standard Deviation
Standard Deviation
The standard deviation is a measure of how spread out the values are from the mean.
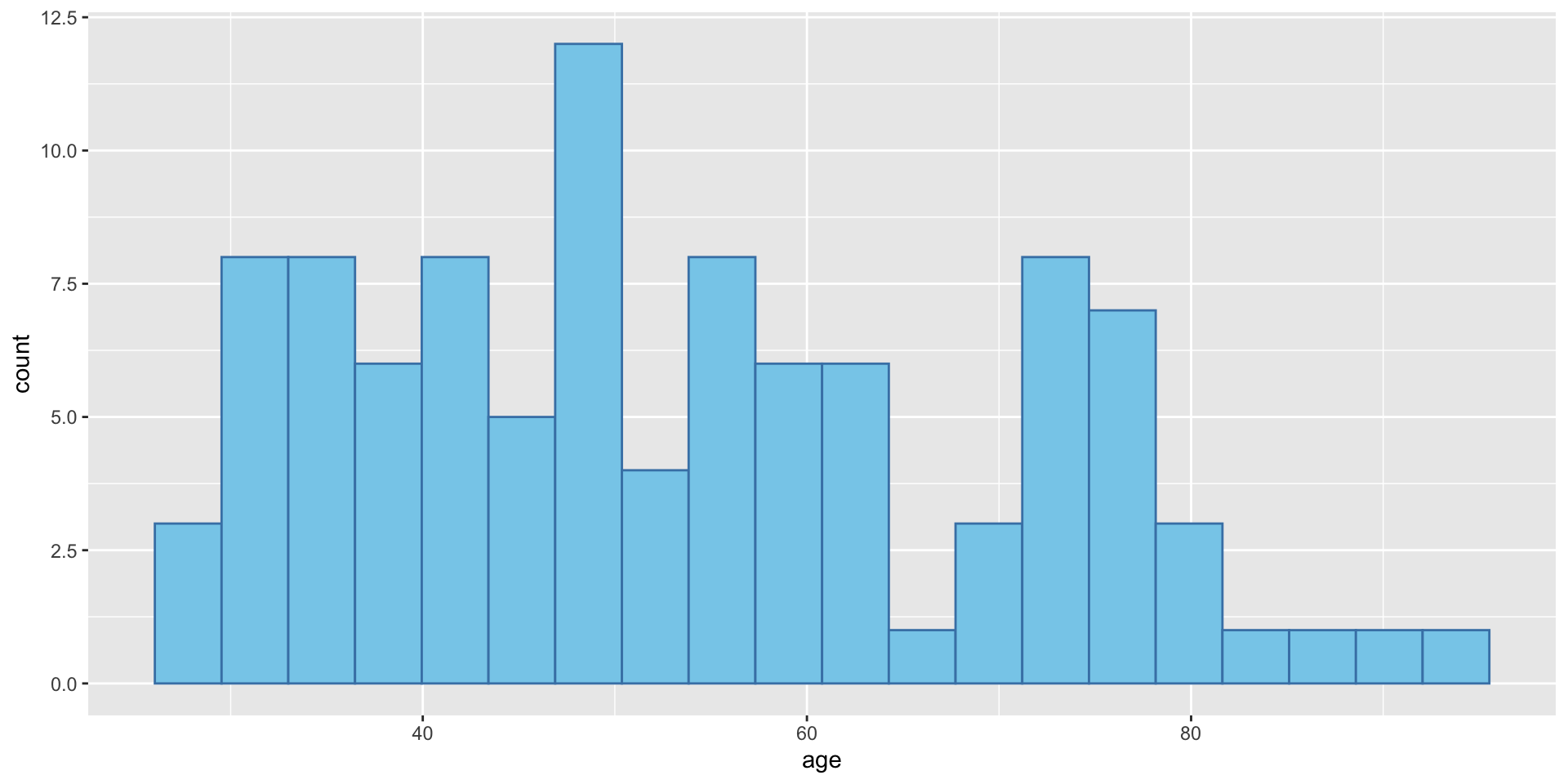
- First let us calculate the standard deviation of the age variable in the BEPS dataset by hand.
- First let us calculate the variance of the age variable in the BEPS dataset by hand.
Sum_square n Var sd
1 376187.3 1525 246.8421 15.71121- With R, we can use the
sd()function to calculate the standard deviation easily.
3 Degrees of Freedom
Why we use n()-1 instead of n() in the variance formula? When we calculate the variance, we use the mean of the sample, which itself is estimated from the sample. For example, if we have a sample of 10 numbers, the mean of the 10 numbers is decided by the 10 numbers. But if we know the mean of the 10 numbers, you are free to choose the 10 numbers. Actually, not 10 numbers. When you’ve chosen 9 numbers, you will find that you cannot freely choose the 10th number if you wish get the pre-decided mean. Therefore, we only have 9 degrees of freedom in this case.
Degrees of Freedom
The degrees of freedom is the number of independent observations in a sample minus the number of population parameters that must be estimated from sample data.
4 Standard Error
Standard Error
The standard error is the standard deviation of the sampling distribution of a statistic.
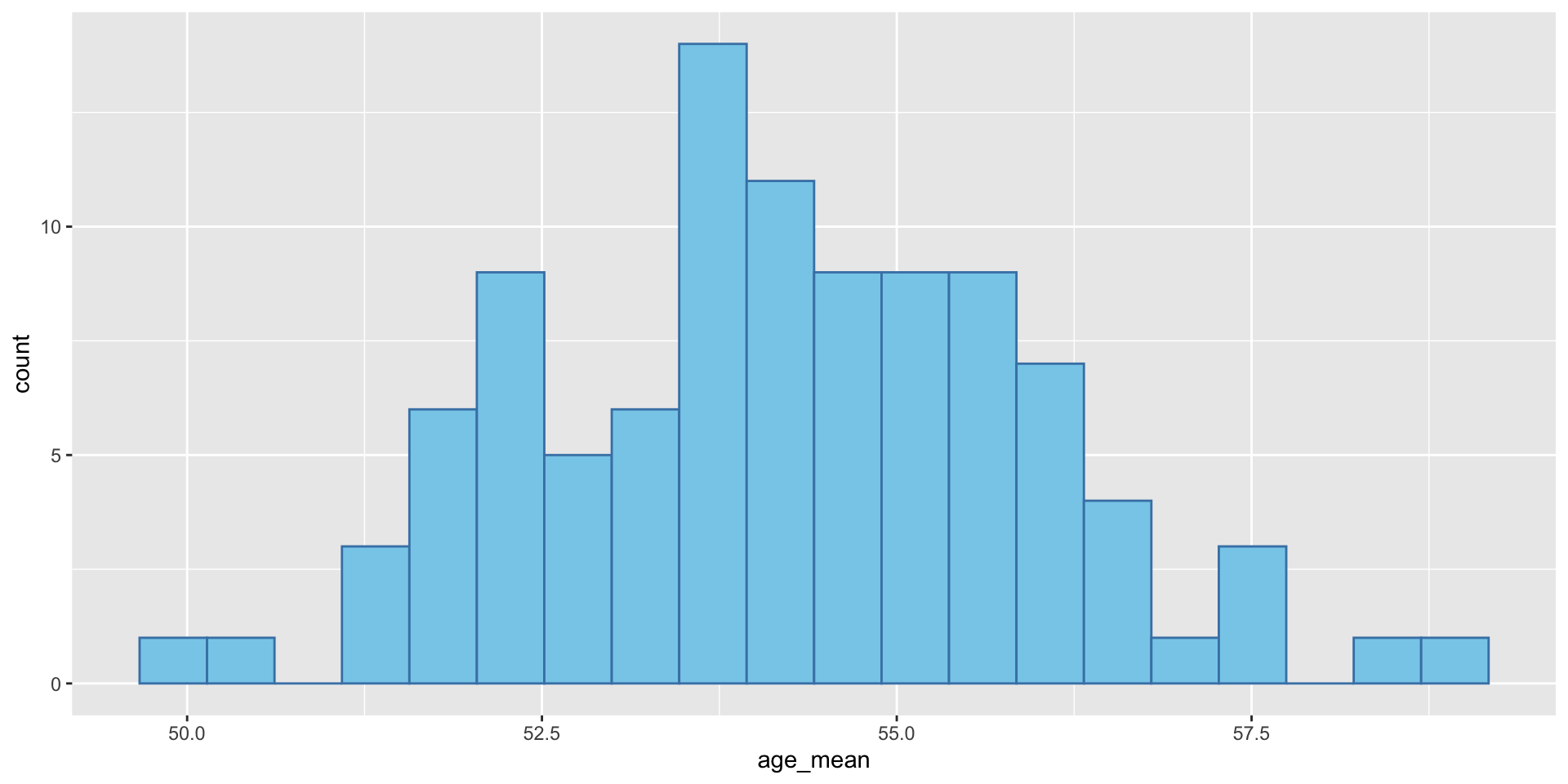
- First let us calculate the standard error of the mean of the age variable in the BEPS dataset by hand.
age_mean
1 54.38Code
# 100 samples
# Don't worry if you don't understand this code. We will learn the for loop function in the future lessons.
age_mean <- numeric(100)
# Loop to generate 100 age_mean values
for (i in 1:100) {
age_mean[i] <- BEPS %>%
select(age) %>%
slice_sample(n = 100, replace = TRUE) %>%
summarise(age_mean = mean(age)) %>%
pull(age_mean)
}
# Display the first few age_mean values
age_means <- data.frame(sample = 1: 100,
age_mean)[1] 1.756995- However, we don’t need to do this by hand. We don’t need to create 100 samples either. Even it is possible to survey 100 samples, it is time-consuming and costly. There is a easier way to calculate the standard error of the mean.
age_mean sd se
1 52.8 15.21031 1.521031We can see that the se calculated by sd√(n) is very close to the sd of the 100 age_mean values we calculated before.
We can easily notice that the standard error of the mean is dependent on the sample size (n). The larger the sample size, the smaller the standard error of the mean.
However, if we increase the sample times but keep the sample size unchanged, the standard error of the mean will not change significantly.
5 Recap
-
In this lesson, we learned the standard deviation and the standard error.
The standard deviation is a measure of how spread out the values are from the mean.
The standard error is the standard deviation of the sampling distribution of a statistic.
The standard error of the mean is dependent on the sample size (n). The larger the sample size, the smaller the standard error of the mean.
In the following lessons, we will use sampling distribution and the standard error to calculate the confidence interval of the mean, and do hypothesis testing.
Thank you!


