R programming for beginners (GV900)
Lesson 9: Normal distribution ~ Part 2
Friday, January 12, 2024
2 Find out the probability of the data
Unlike discrete data, the y axis in continuous data does not represent the probability of the data.
We can only use the area under the curve to describe the probability of the continuous data.
We can use CDF (Cumulative Distribution Function) to calculate the probability of the data.
\(F(x)\) represent the probability of the data less than x, i.e., the area under the curve to the left of x.
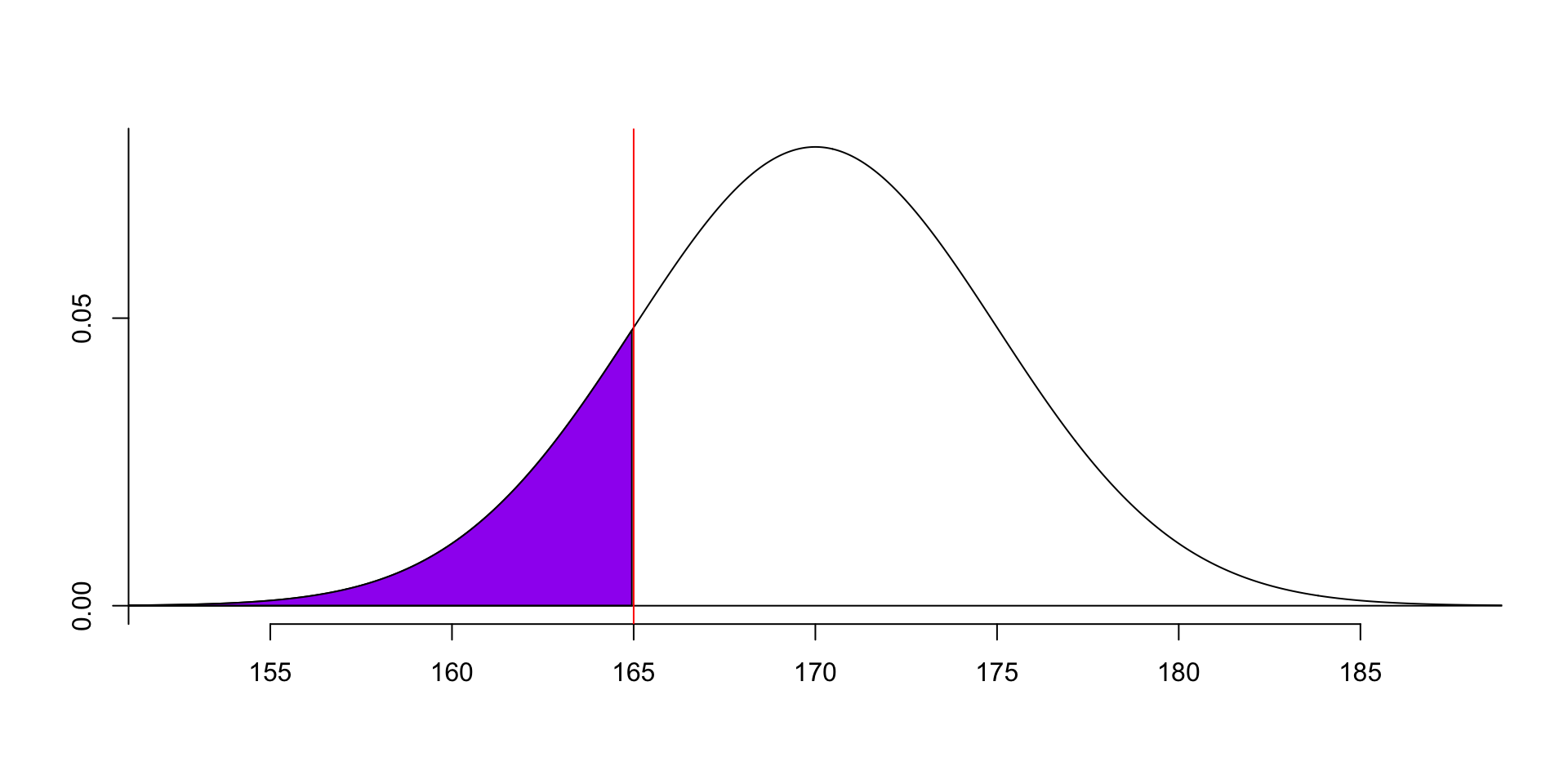
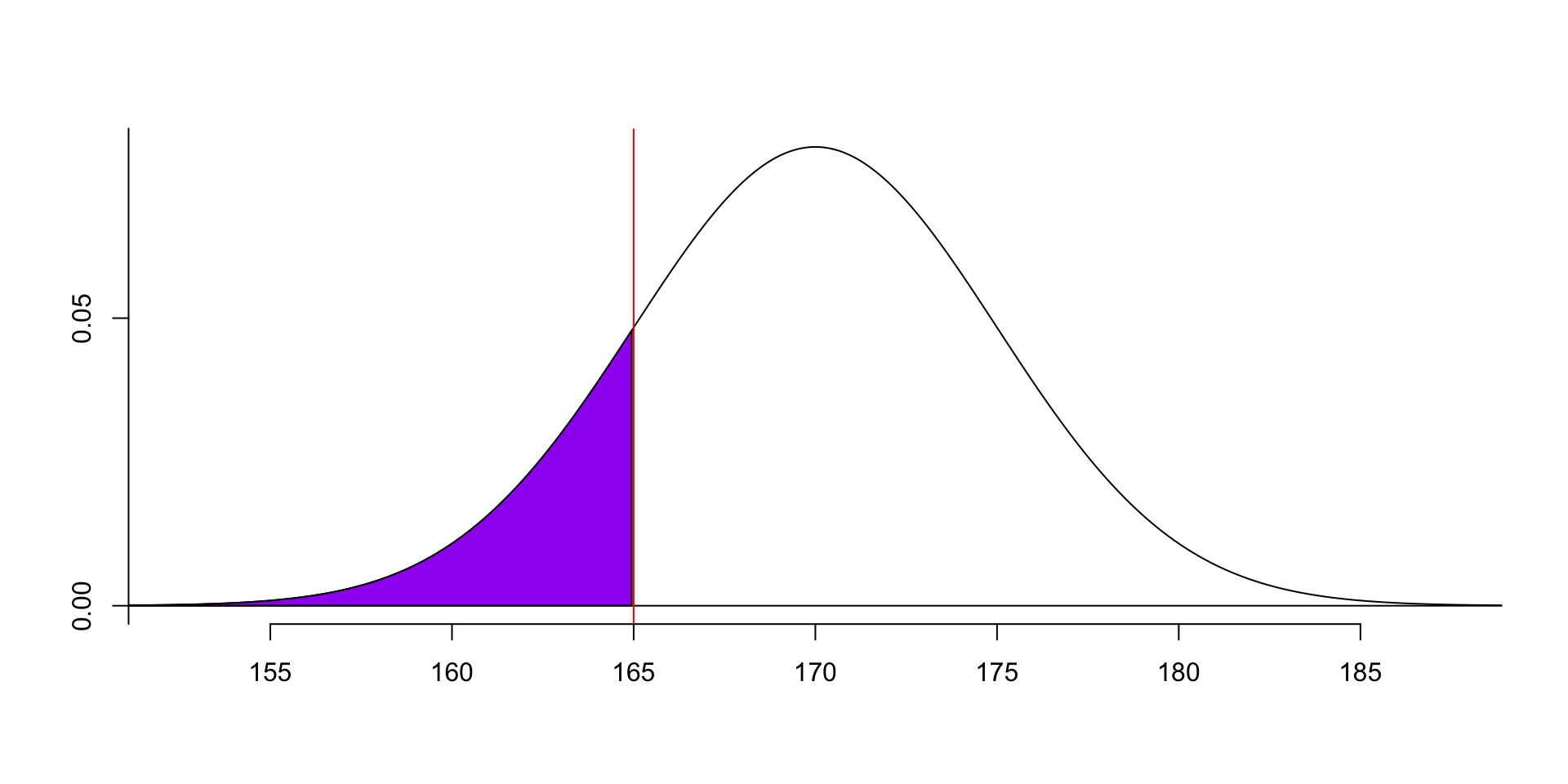
For example, we can calculate the probability of the data is less than 165: \(F(165) = P(x<165) = ?\).
- We can use R function to find out the probability easily.
- The first argument is the value of the data.
- The second argument is the mean of the data.
- The third argument is the standard deviation of the data.
- This example shows that the probability of the data is less than 165 is 0.1587, i.e. 15.87%.- We can also calculate the probability of the data is greater than 165: \(P(x>165) =?\).
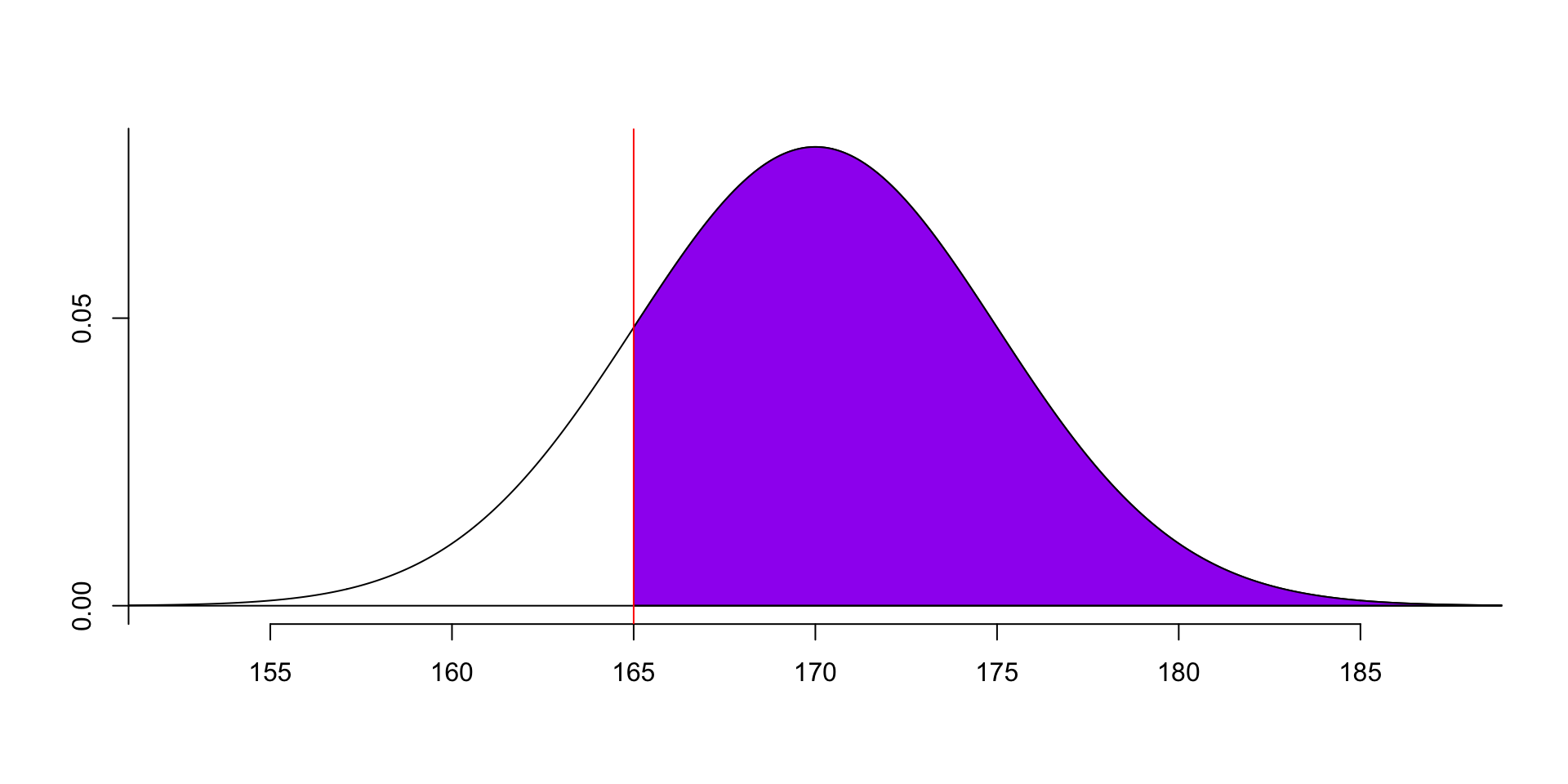
[1] 0.8413447- \(lower.tail = FALSE\) means that we want to calculate the probability of the data greater than 165.
- This example shows that the probability of the data is greater than 165 is 0.8413, i.e. 84.13%.
- Actually, since the total area under the curve is 1, we can calculate the probability of the data greater than 165 by subtracting the probability of the data is less than 165 from 1: \(P(x>165) = 1 - P(x<165) = 1 - F(165)\).
[1] 0.8413447No surprise, the result is the same as the above.
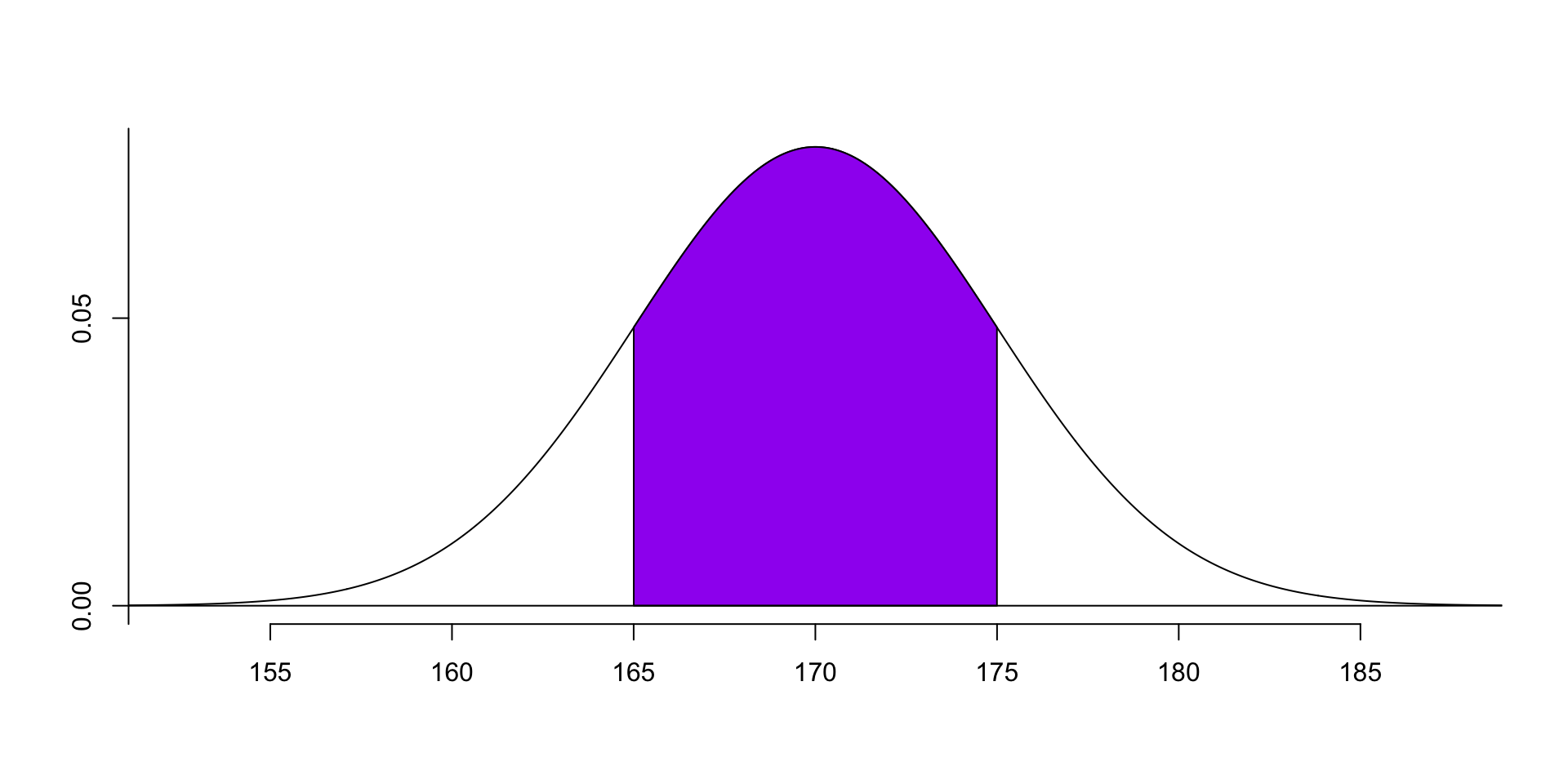
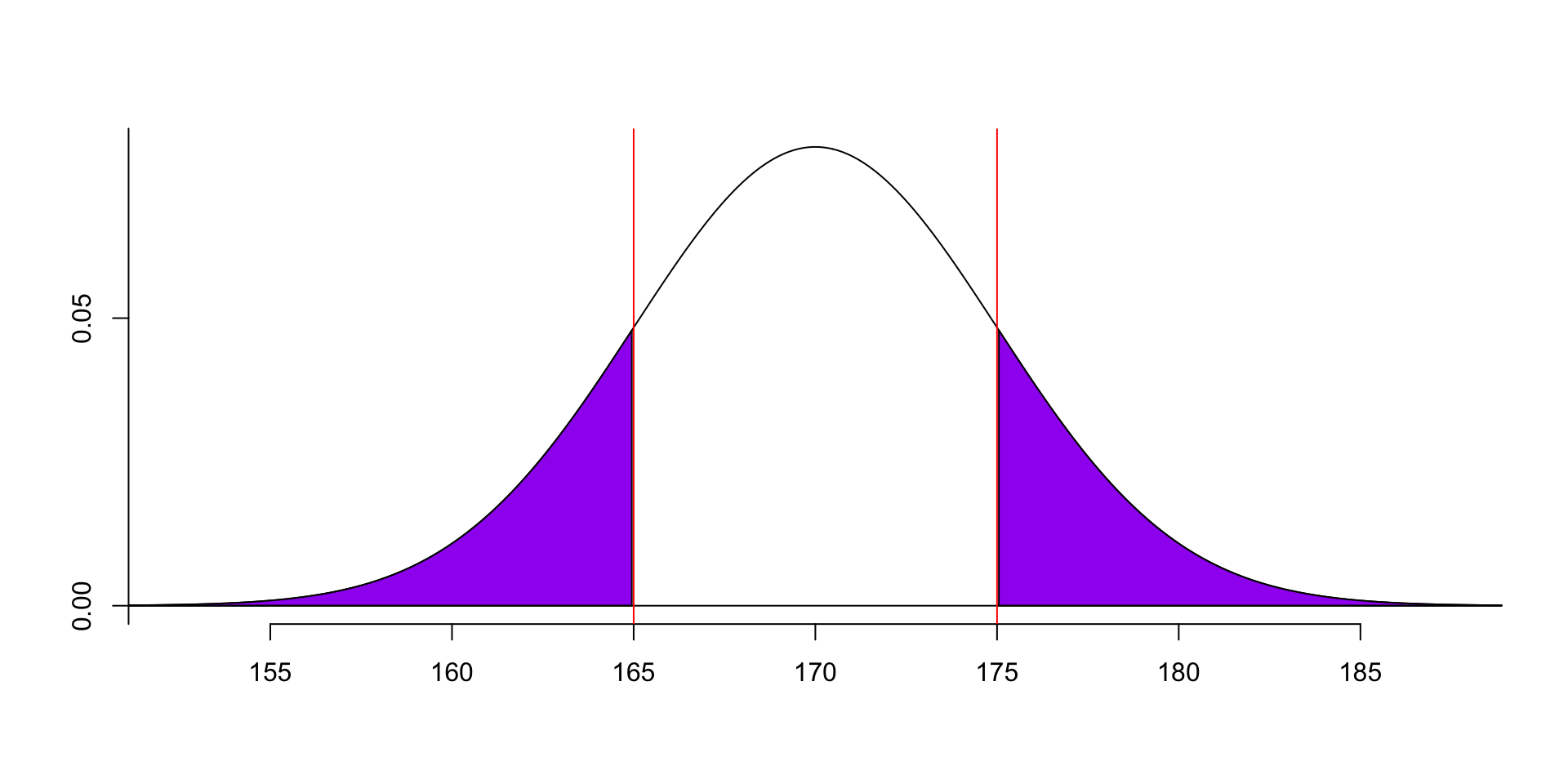
We can also calculate the probability of the data is between 165 and 175: \(P(165<x<175) = ?\).
We have plenty of ways to calculate it.
We can calculate the probability of the data less than 175 first, then subtract the probability of the data less than 165 from it: \(P(165<x<175) = P(x<175) - P(x<165) = F(175) - F(165)\).
i.e., we use the area of the following purple part:
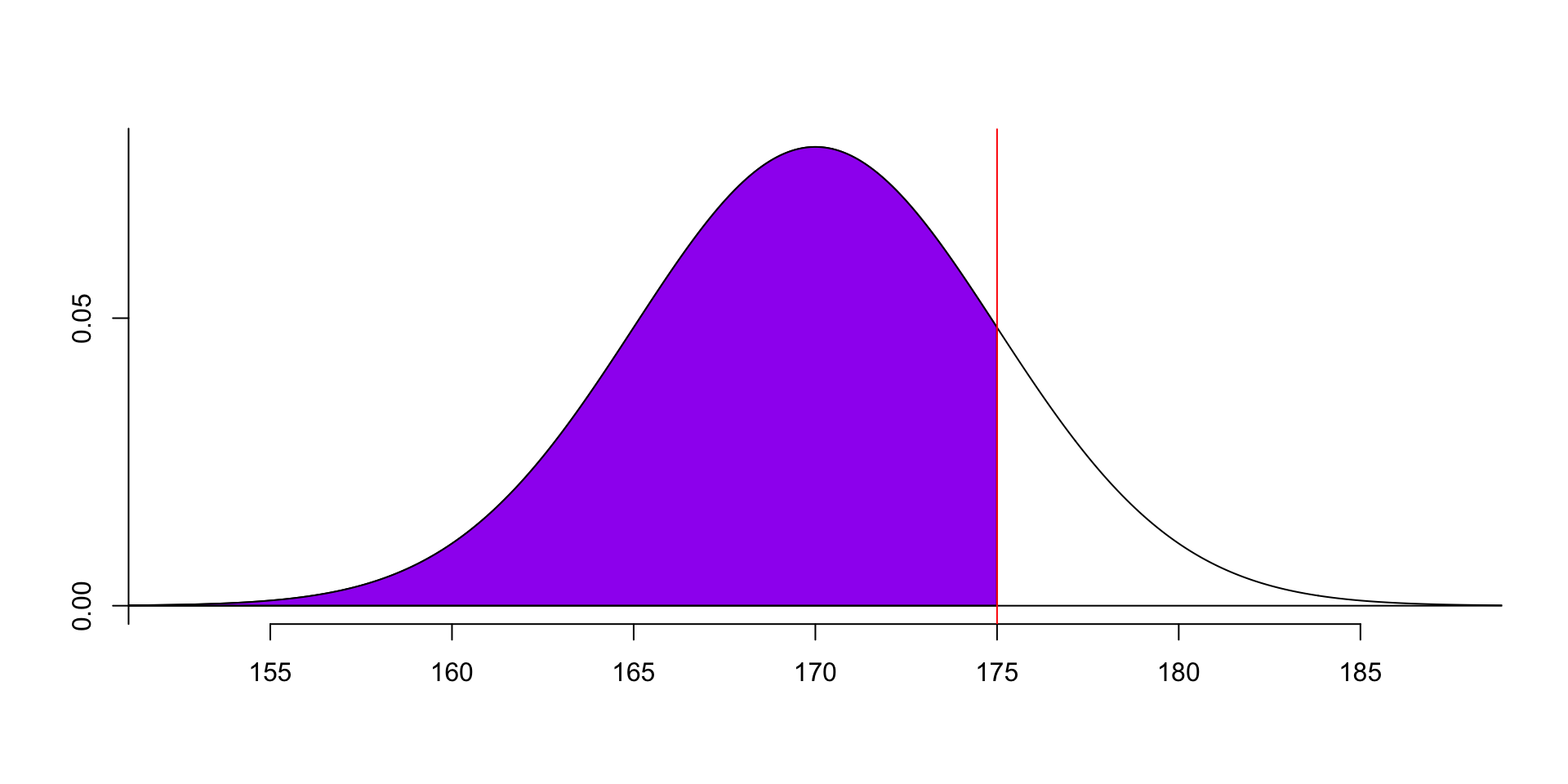
- minus the area of this part:
- In R, we can use the following formula to calculate it.
[1] 0.6826895This example shows that the probability of the data between 165 and 175 is 0.6827, i.e. 68.27%.
Remember that the total area under the curve is 1, so the probability of the data between 165 and 175 is 1 minus the probability of the data less than 165 and greater than 175: \(P(165<x<175) = 1 - P(x<165) - P(x>175) = 1 - F(165) - (1 - F(175))\).
So we can use 1 minus the following two parts to calculate it.
- In r, it would be like this:
[1] 0.6826895No surprise, the result is the same as the above.
Remember that the normal distribution is symmetrically distributed around the mean, so the probability of the data less than 165 is the same as the probability of the data greater than 175, because the distances from 165 and 175 to 170 is the same: \(P(x<165<175) = 1 - 2 \times P(x<165)\).
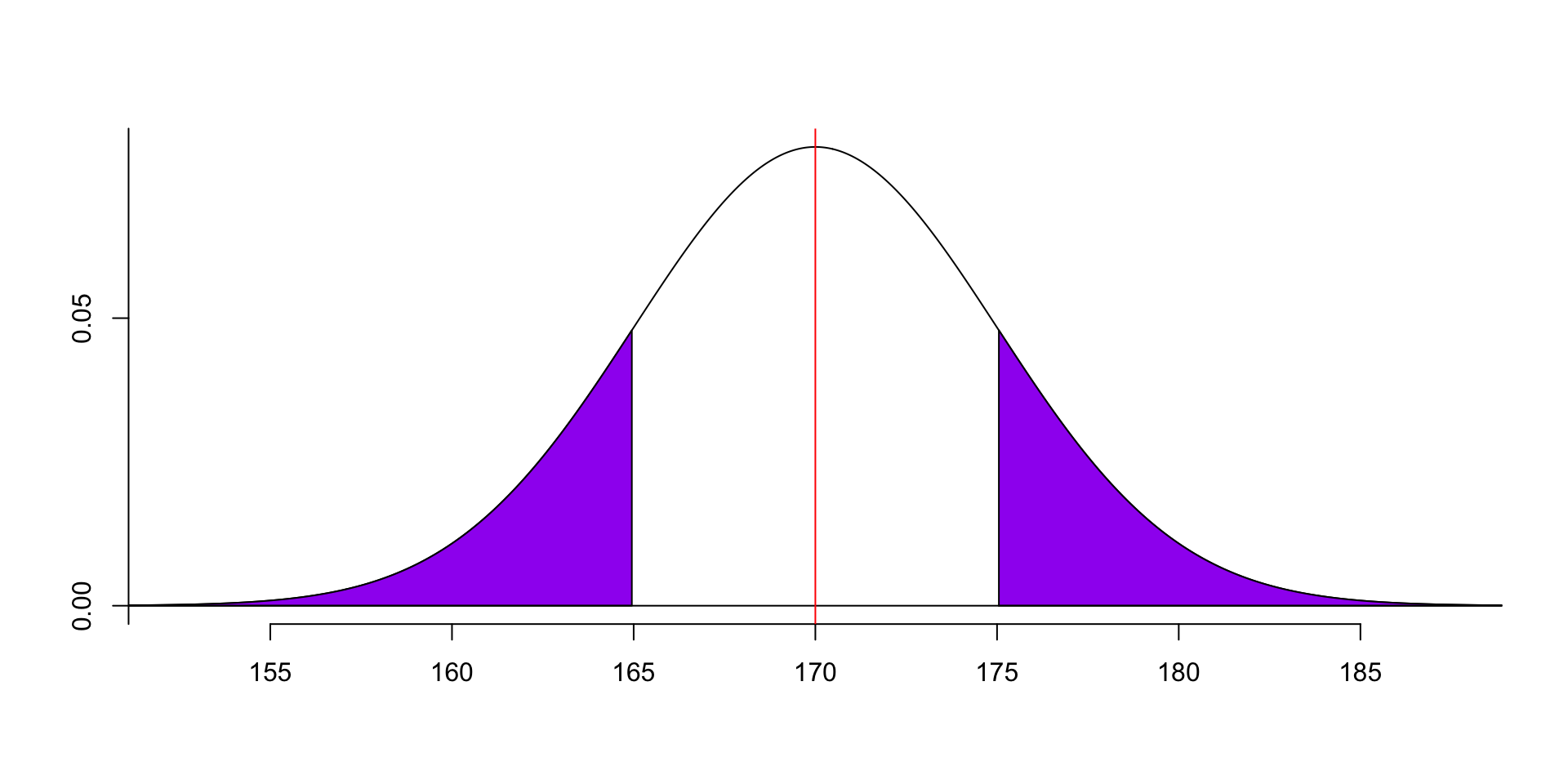
- So, we can use the following formula to calculate the probability even simpler.
3 Find out the critical value if we know the probability
- We can also use CDF to find out the critical value if we know the probability.
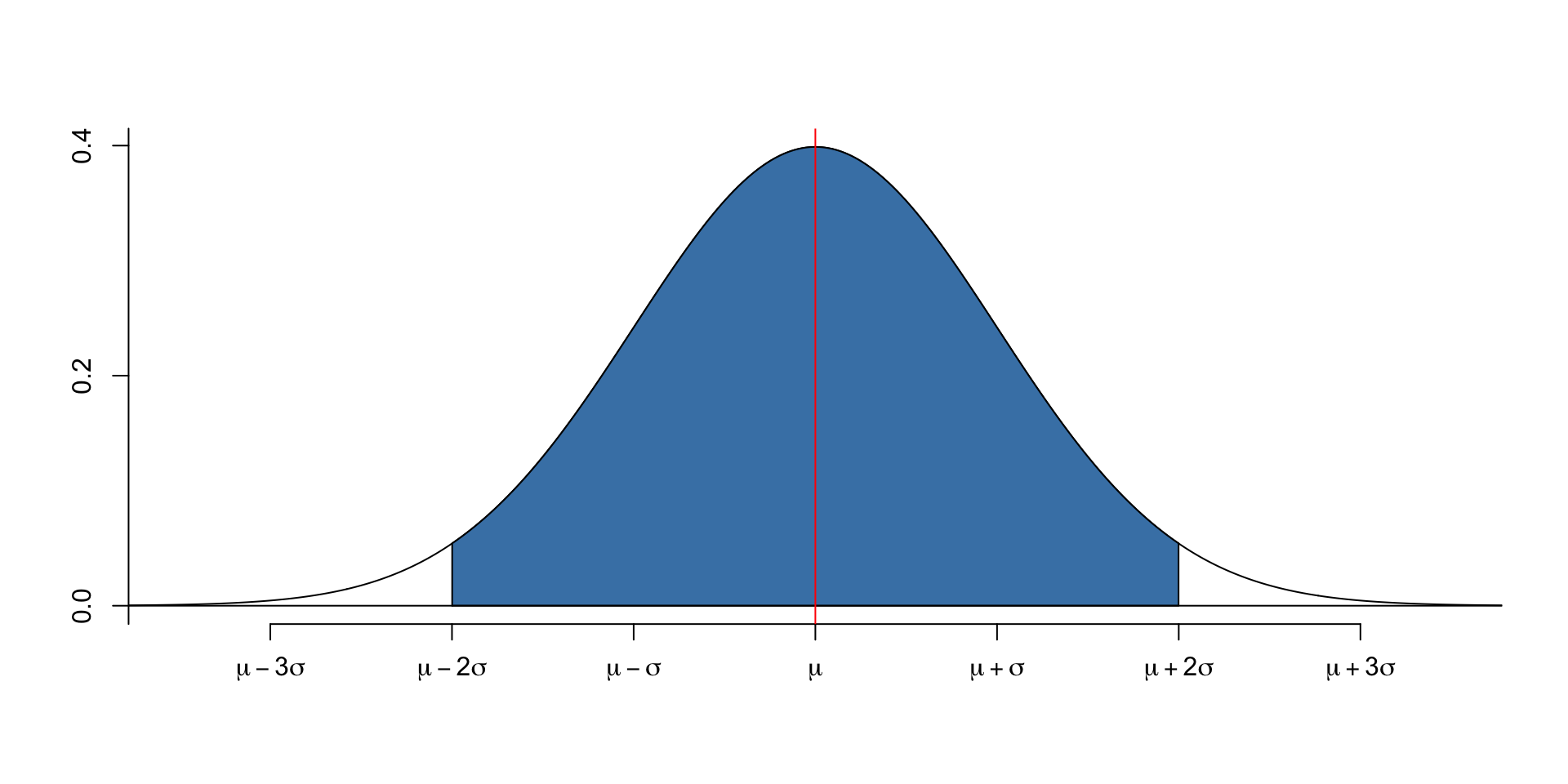
- First, understand the 68-95-99.7 rule.
- 68% of the data is within 1 standard deviation of the mean.
- 95% of the data is within 2 standard deviations of the mean.
- 99.7% of the data is within 3 standard deviations of the mean.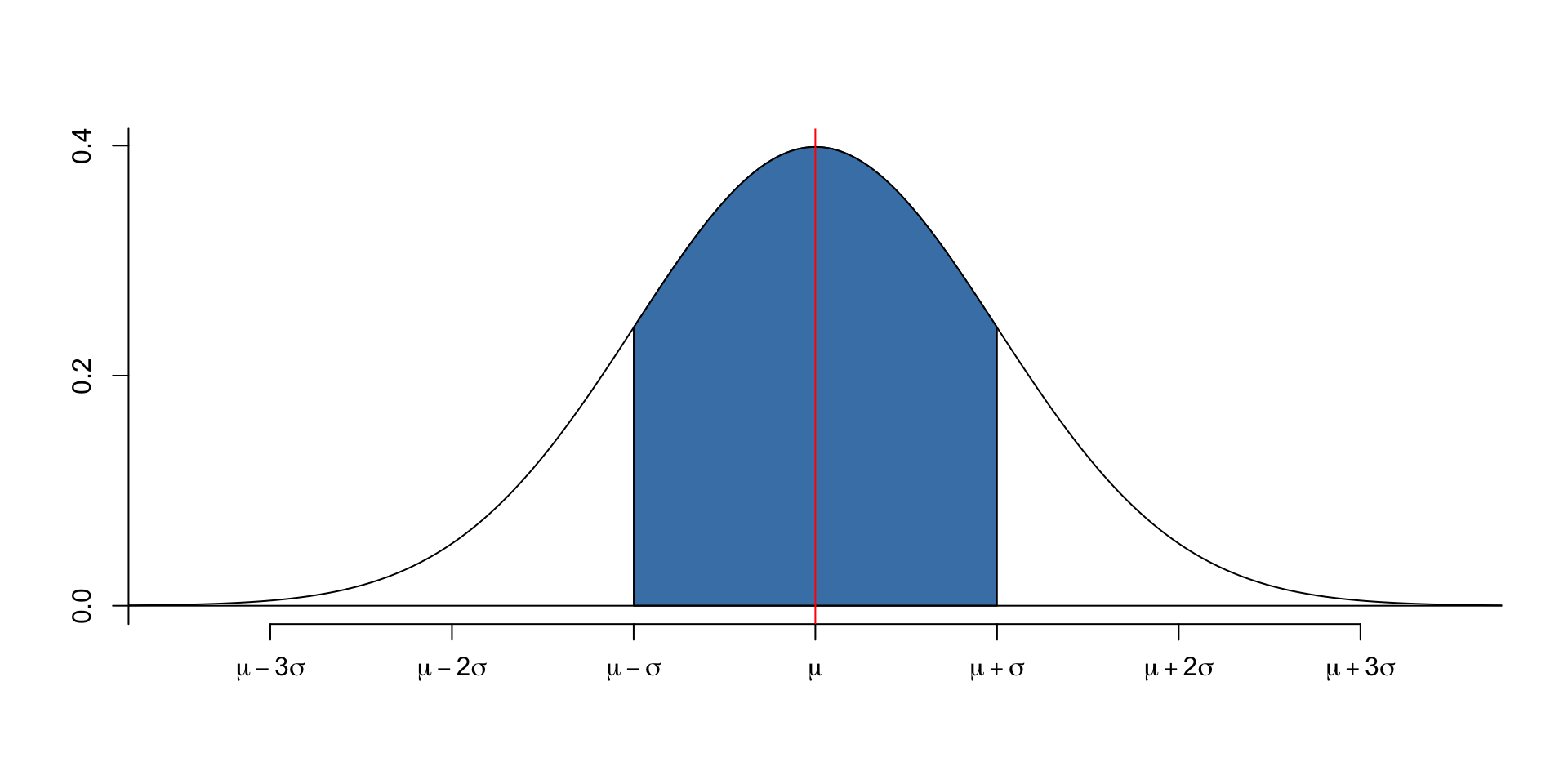

-
qnorm()function
- If it is not exactly the above probability, we can easily use R function
qnorm()to find out the critical value.
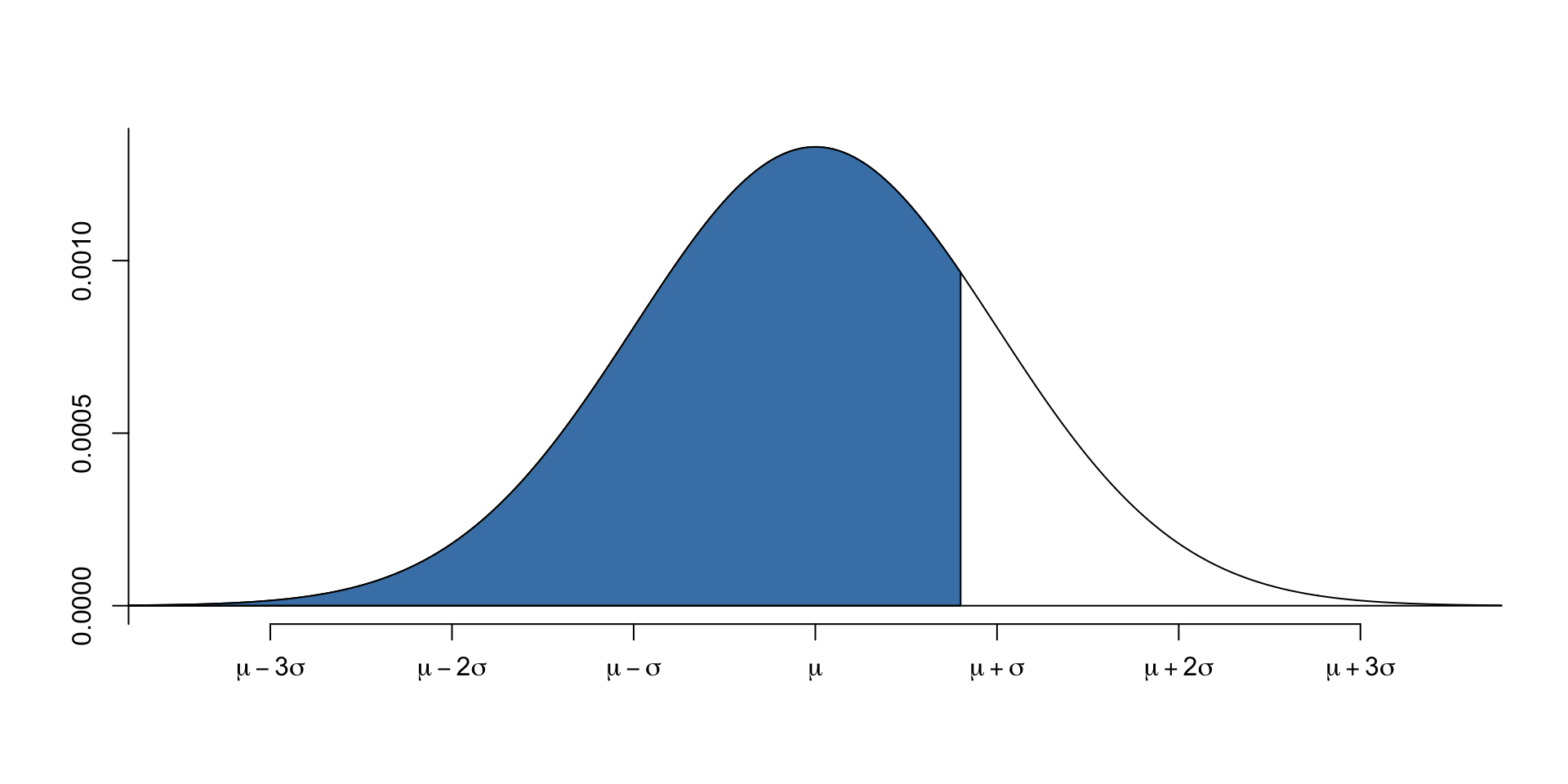
[1] 1741.926- The first argument is the probability of the data.
- The second argument is the mean of the data.
- The third argument is the standard deviation of the data.
- This example shows that if the probability to the left of the data is 0.79, then the critical value of the data is 1742.- We can also calculate the critical value of the data if we know the upper side probability.
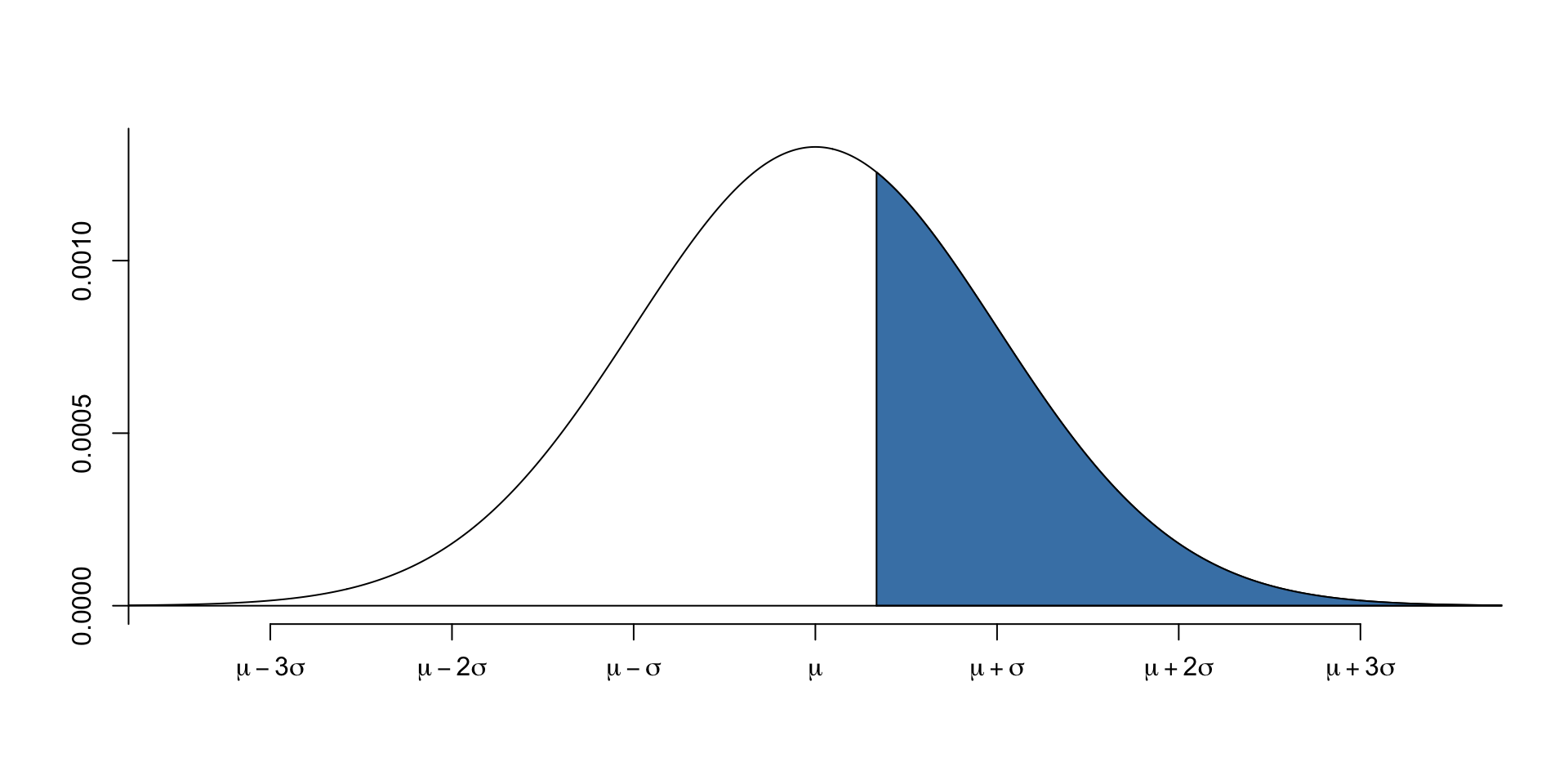
- $lower.tail = FALSE$ means that we want to calculate the value of the data with probability to the right of the data.
- This example shows that if the probability to the right of the data is 0.37, then the value of the data is 1600.We can also calculate the critical values of the data if we know the probability between the data.
For example, we can calculate the value of the data between probability 0.2 and 0.75.
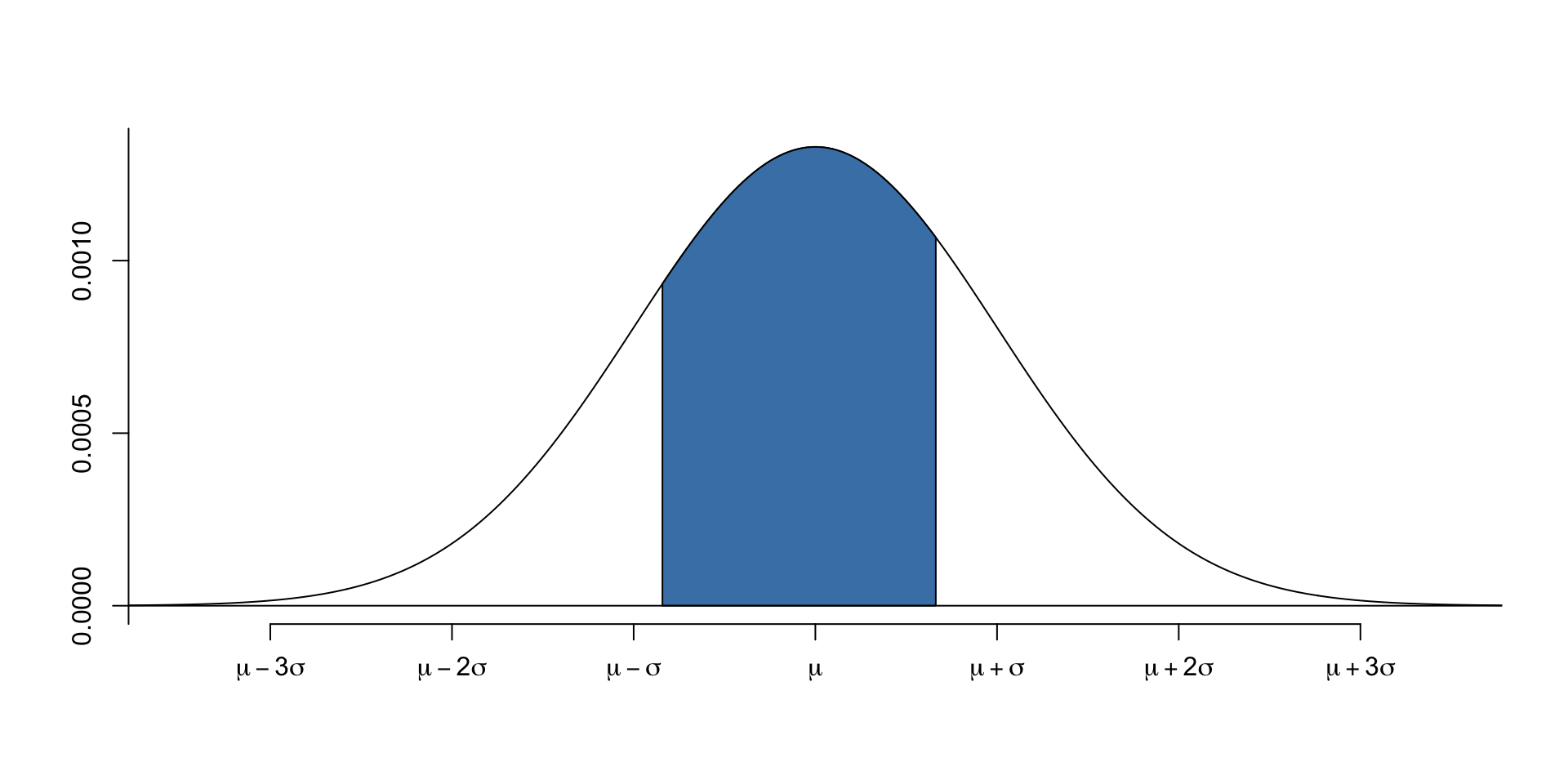
[1] 1247.514 1702.347- This example shows that if the probability to the left of the data is 0.2, then the left critical value of the data is 1248; if the probability to the left of the data is 0.75, then the right critical value of the data is 1702.4 Generate normal distribution data
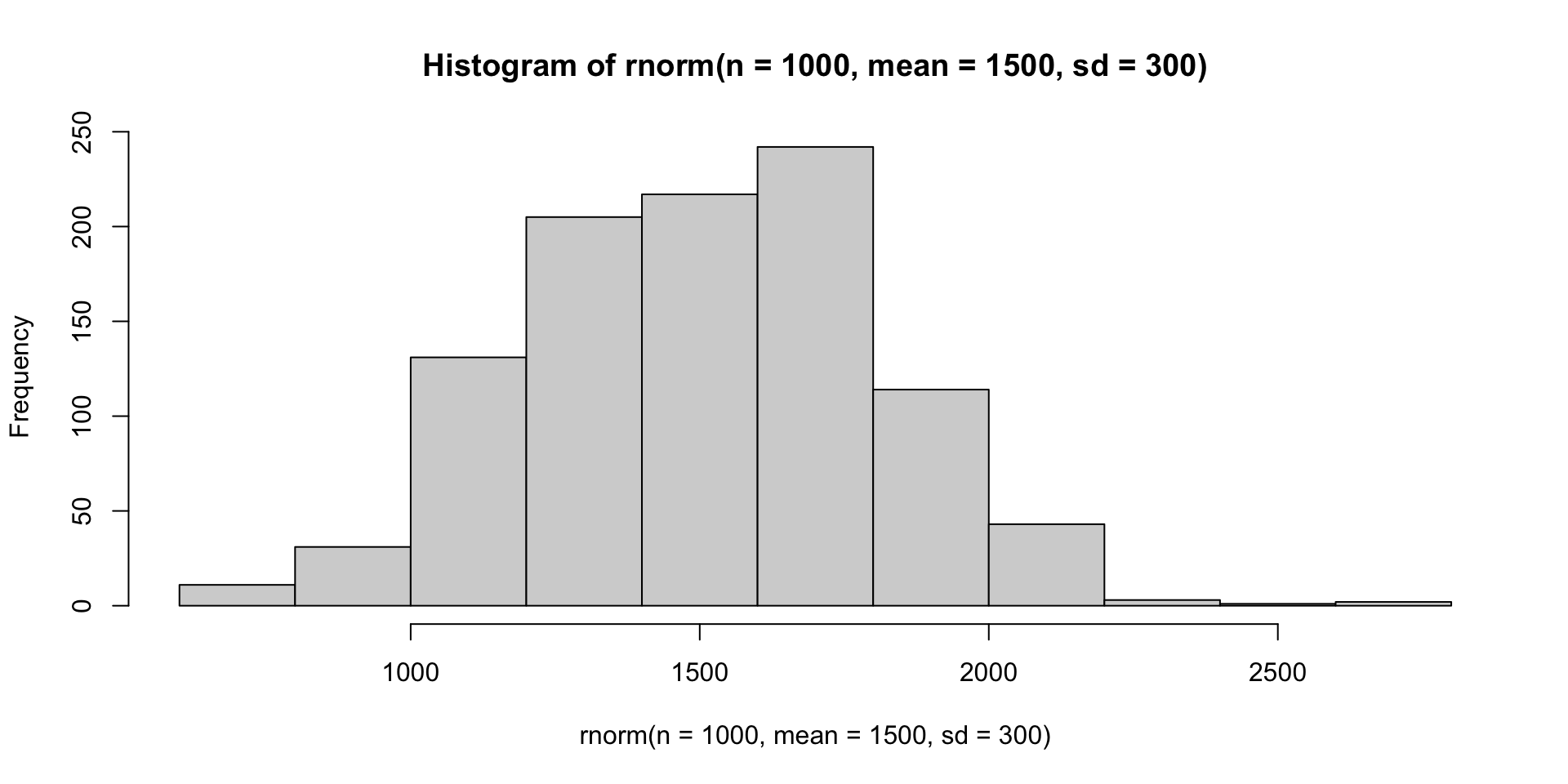
- We can use
rnorm()function to generate normal distribution data.
[1] 0.95130004 0.12061804 -0.42174915 0.09952709 0.79155243 -1.26001000The first argument is the number of data we want to generate.
The second argument is the mean of the data.
The third argument is the standard deviation of the data.
We can use
hist()function to plot the data.
5 Standard normal distribution
During the period when there is no computer, people have to calculate the CDF by hand.
However, the PDF and CDF of standard normal distribution are quite complicated. It is hard to calculate, time-consuming, and easy to make mistakes.
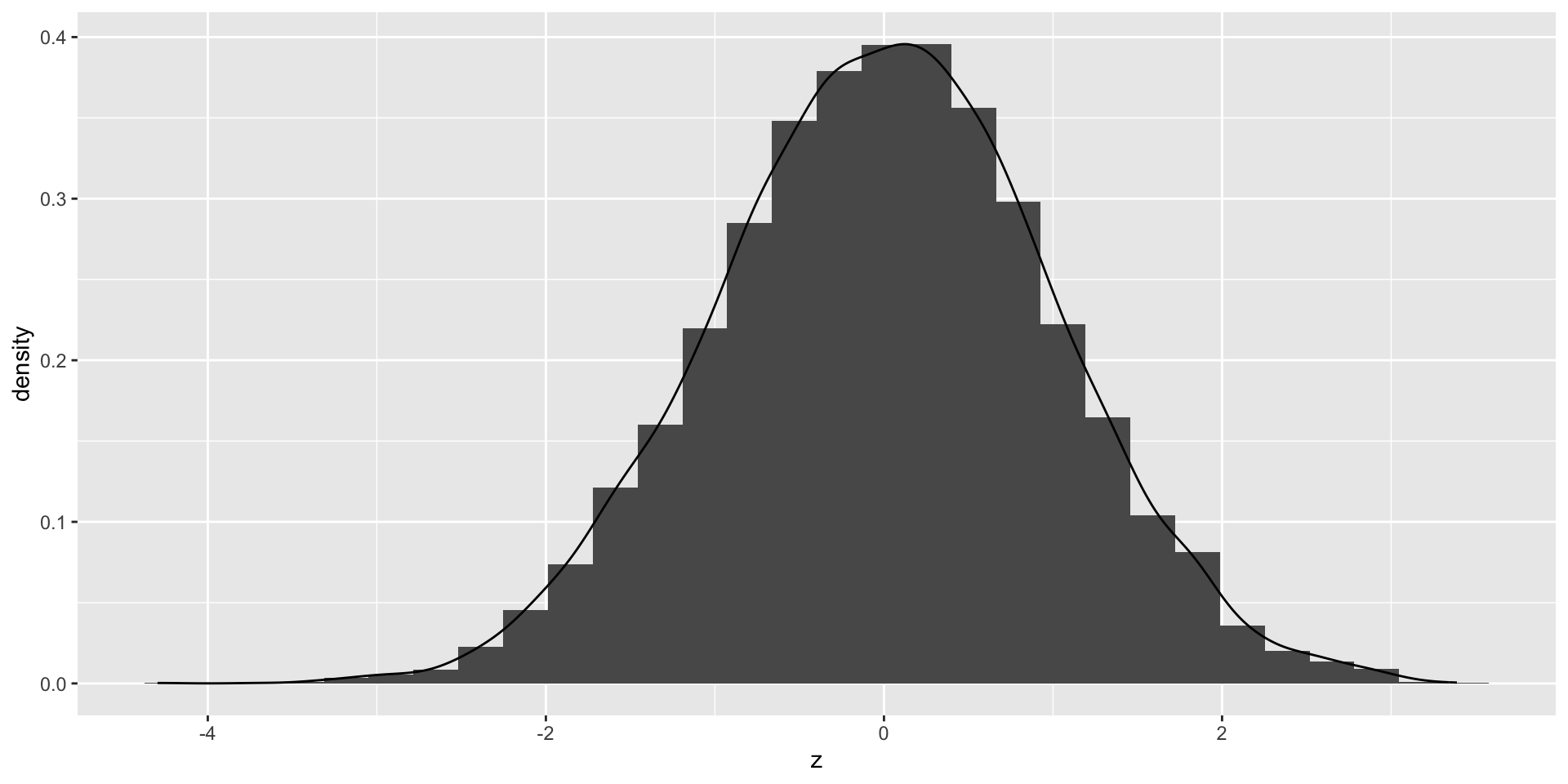
To make it simple to calculate, we can standardize the normal distribution.
- PDF of standard normal distribution
- The pdf formula of standard normal distribution is:
\[ f(x) = {1 \over \sqrt{2\pi}} e^{-{x^2 \over 2}} \]
- CDF of standard normal distribution
- The cdf formula of standard normal distribution is:
\[ \Phi(x) = \int_{-\infty}^x f(x) dx = \int_{-\infty}^x {1 \over \sqrt{2\pi}} e^{-{x^2 \over 2}} dx \]
- Compare to general normal distribution below:
\[ f(x) = {1 \over \sqrt{2\pi\sigma^2}} e^{-{(x-\mu)^2 \over 2\sigma^2}} \]
- the mean and standard deviation of standard normal distribution are 0 and 1, respectively.
\[ \mu = 0 \] \[ \sigma = 1 \]
- Standardize the normal distribution
- We use an example to show how to standardize the normal distribution.
- Application of standard normal distribution
We can use standard normal distribution to compare two data with different mean and standard deviation.
For example, we have two data of exam scores, a is 2000 and b is 89 with mean 1500 and 75, and standard deviation 300 and 5, respectively. We want to know which score is better.
We can standardize the two data first, then compare their z scores.
We can see that the z score of 2000 is 1.67, and the z score of 89 is 2.8. So the score of 89 is better than the score of 2000.
We can also use
pnorm()function to calculate the probability of the two scores
Thank you!

